Deconstructing the AI Supply Chain Layers
Understand how AI’s hardware, cloud, data, and model layers create a sustaining innovation that reinforces Big Tech dominance.
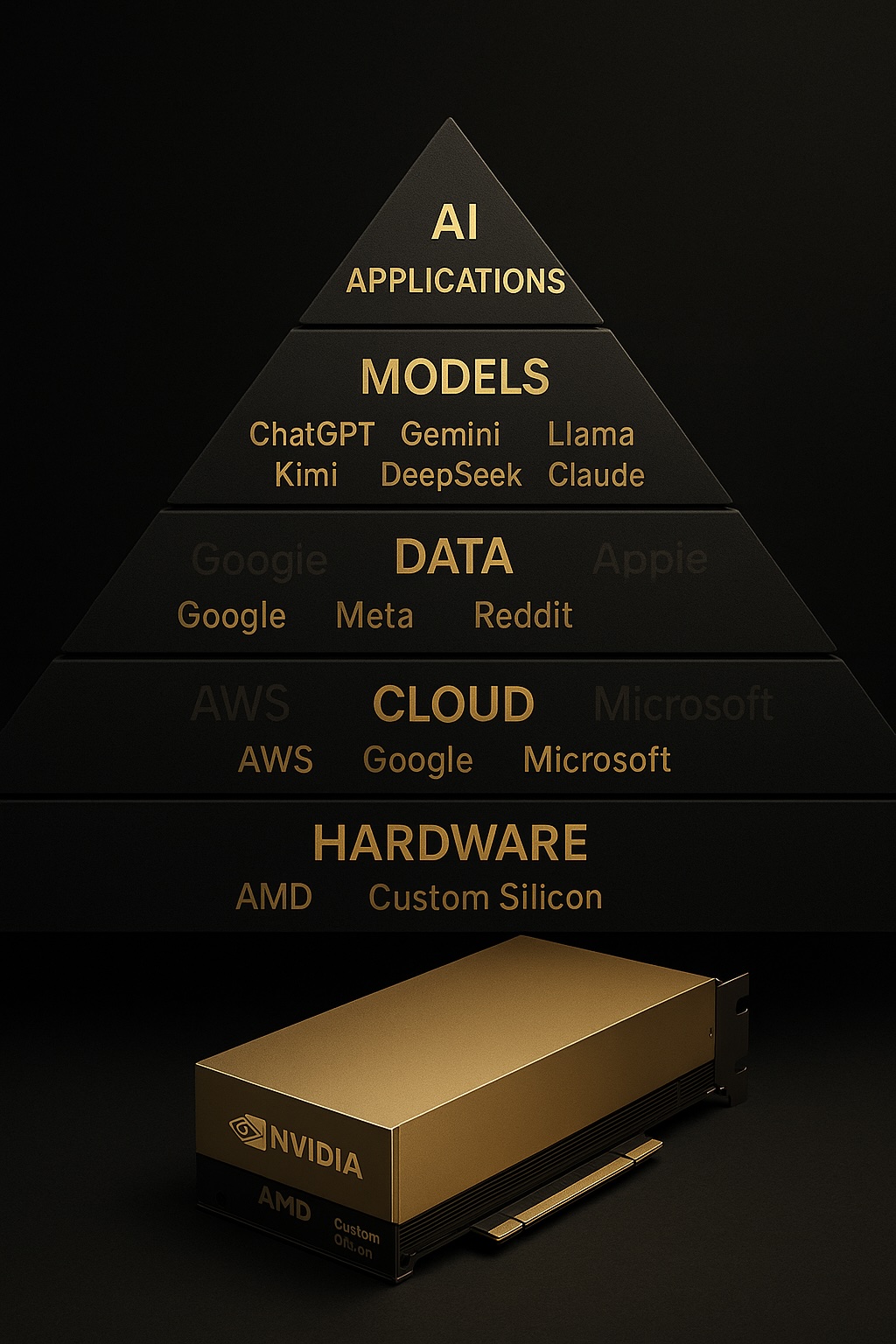
AI is often described as a disruptive force that will change everything, but the real picture looks very different once you take a step back to really see who controls each of its layers. The deeper you look, the clearer it becomes that AI appears more as a sustaining innovation as it is consolidated amongst the same companies that already run the digital world.
The AI supply chain is not a flat playing field because it runs through five tightly linked layers. These layers are Hardware, Cloud Infrastructure, Training Data, Foundation Models and Applications. Each one reinforces the next, and the companies already dominating those layers remain in control.
This guide maps the stack clearly so that you can see why Big Tech gets stronger with AI rather than weaker. The goal is not to hype the technology but to show the structural forces shaping who wins and who survives.
The Hardware Layer: The Silicon Foundation
If you start at the bottom of the AI stack, you find a single company shaping the pace of global innovation. Nvidia is not one competitor among many because it is the supplier that defines what the rest of the industry can build.
Few year ago, when my entire operations workflow depended on one overworked team member. If he slowed down, the entire system would stall stalled because everything invisible in the workflow ran through him.
The AI industry is in the same position with Nvidia. You can talk about challengers, but the reality is that everyone depends on Nvidia’s GPUs to train and deploy serious models.
When a single company holds the keys to the fastest compute, the entire world moves at the speed that company allows. The parallel to my own business was uncomfortable, because I am seeing the same single point of failure at a global scale.
Nvidia controls roughly ninety percent of the AI GPU market, which gives it pricing power that would be impossible in a competitive market. The margin profile tells the story clearly because hardware never carries 70% gross margins unless demand is unlimited and alternatives are weak.
CUDA, which is Nvidia’s software layer, is the real lock. Developers who have built their models on CUDA cannot switch without rewriting years of code, which means Nvidia’s moat is not just hardware but the entire ecosystem around it.
Big Tech’s custom silicon programs are defensive rather than revolutionary. Google TPUs, Amazon Trainium and Meta MTIA exist to reduce dependency, not to dethrone Nvidia. These giants build their own chips, but they still buy enormous volumes from Nvidia because training frontier models still depends on Nvidia’s speed.
The economics are painful for everyone else. Training clusters cost billions, and hardware depreciation becomes a quiet financial time bomb because chips become obsolete faster than companies admit.
Key Takeaway
If you do not control hardware, you do not control the foundation of AI. The companies that sit on the silicon are the ones AI strengthens, and everyone else plays on borrowed time and rented speed.
The Cloud Infrastructure Layer: The Compute Factories
If Nvidia controls the muscle of AI compute, the hyperscalers control the gates. You cannot build or scale any serious AI system without paying rent to AWS, Azure or Google Cloud.
When my delegation failed in my own business, the problem was never the people doing the work. The failure was always hiding inside the system I developed to support them and the plumbing that no one sees.
AI’s infrastructure works the same way, except most of the plumbing is owned by three companies. If a hyperscaler tightens capacity or raises pricing, every company using AI will feel the shock immediately.
The pattern is identical to the fragile workflows I dealt with in my business. You can have great output at the top, but if the foundation slows, everything collapses.
AWS holds about 31% of the global cloud market, Azure sits at roughly 24%, and Google Cloud carries around 11%. This creates a highly concentrated layer that behaves like an oligopoly because the fixed costs involved are too large for new entrants to compete.
Moving away from a hyperscaler is almost impossible once you are inside. You depend on their tools, their storage systems, their well integrated services and their pricing structure, and the egress fees punish any attempt to leave.
The neocloud providers like CoreWeave look like challengers, but they survive mainly because the hyperscalers need extra capacity to meet growing AI demand. These partnerships reinforce the existing hierarchy rather than threatening it.
Massive capex commitments from players such as OpenAI flow directly back into hyperscaler pockets. The gigantic data center buildout is not a democratized effort but a reinforcement of existing power.
Key Takeaway
Nvidia decides how fast AI can move, and the hyperscalers decide who gets to move at all. This layer does not disrupt Big Tech, it strengthens its grip.
The Training Data Layer: The Digital Crude Oil
Most people assume compute is the scarce resource in AI, but the real scarcity sits in data. Not generic internet text, but high quality behavioral and labeled data that carries meaning and structure.
My delegation problems years ago came down to one truth. Not everyone especially new hires have the years of client context that old timers had, so even good people produced uneven results because they lacked the data that shapes good judgment.
AI is facing the same structural bind. You can buy GPUs, but you cannot buy fifteen years of user behavior data because that sits inside Google, Meta, Amazon and Apple.
These companies own the most valuable form of data which is the long tail record of human actions and decisions. That data is the real source of power, not the algorithms built on top of it.
Big Tech has a twenty year head start on behavioral data. Search logs, social interactions, purchase histories, maps usage and device telemetry create a depth of signal that no open dataset can match.
High quality human written text on the internet will run out by 2026, which forces labs to look for alternative sources. This is why you see mass transcription of YouTube videos and quiet licensing deals with publishers.
Now Apple has focussed heavily on Privacy over the years, winning them a huge chunk of customers for their devices. Now the same privacy structure is hindering them from developing good models that work as good as other who had no such restrictive data storage policies.
The real bottleneck is labeled data which requires humans to correct, compare, refine and score model outputs. This hidden labor force supplies the intelligence that AI cannot generate on its own, and only the largest players can afford millions of human evaluations.
Key Takeaway
Compute can be bought and cloud can be rented, but behavioral and labeled data is owned. That ownership locks the structure of the AI industry into the hands of the companies that collected it long before the current wave began.
The Foundation Models Layer: The Engines of Intelligence
People treat the model layer as the centre of the universe, but it is only the most visible layer. The real power sits underneath it, shaping what the models can become.
In my company, I expected my team to compensate for weaknesses in the system, but they could not escape the constraints I had built. They were limited by the workflows beneath them, not their own capability.
Foundation models operate under the same reality. They are bound by the hardware, cloud and data they rely on, so any weakness in those layers becomes a ceiling on their ability.
This is why only a small set of labs dominate despite hundreds of models appearing in the market. The foundation decides the ceiling.
OpenAI, Google DeepMind and Anthropic dominate the model landscape because they sit closest to the supply chain chokepoints and can afford repeated scaling cycles. GPT-4 captured roughly sixty nine percent of generative AI revenue in 2023, which shows how concentrated actual usage is. Other players are catching up but Open AI still dominates even in 2025.
Open source models expand access but do not shift structural control. They still depend on Nvidia hardware, hyperscaler cloud and data sources that are often out of reach.
Scaling laws reward capital rather than creativity because AI model improvements come from more compute, more data and more training runs. Reasoning improvements still depend on large quantities of human feedback and repeated tuning cycles that only the giants can fund.
Key Takeaway
Models do not create power. They amplify the power already held by whoever controls the lower layers of the stack.
The AI Applications Layer: Where Value Gets Captured
This is the layer everyone gets excited about. It is also the layer where most founders lose because they underestimate how much distribution shapes outcomes.
When I redesigned my delegation system, I learned that the top layer of a workflow holds the least power. The system underneath determines whether the work succeeds or fails, and the final step only reflects the strength of what came before it.
AI applications follow the same pattern. If you run on someone else’s model, cloud, data or distribution, your upside lives inside their constraints.
Most AI apps look innovative only until a platform giant adds the same feature into a product with hundreds of millions of users. The value shifts instantly to the company with distribution. When Microsoft included Team as part of their Office 365 package, it limited growth opportunity for Slack
SaaS companies are currently integrating AI features faster than they can build user bases, limiting long term lock-in. Distribution advantages allows incumbents to push features across their enormous user base, and that reach outweighs any technical edge a startup might have.
AI does not level the field for application builders. It widens the gap between those with distribution and those without it, and this is why vertical AI apps grow quickly but face a ceiling the moment a giant enters their category.
The application layer behaves like a treadmill because innovation happens quickly, but the platforms control adoption. This gives incumbents a structural advantage that does not diminish as AI advances.
Key Takeaway
Applications ride the stack, they do not reshape it. The companies that own the underlying layers capture the value, while everyone else competes on a surface where power does not originate.
Conclusion
The Pattern
- Hardware is controlled by Nvidia
- Cloud is controlled by AWS, Azure and Google Cloud
- Data is controlled by Google, Meta, Amazon and Apple (limited due to their privacy focus)
- Models are mostly controlled by OpenAI, Google and Anthropic
- Distribution is controlled by the largest platforms on earth
The structure repeats the same conclusion. AI strengthens the incumbents who already owned the foundations of the digital world.
Geopolitics
The only external force capable of shifting the stack is the rivalry between the United States and China. Export controls, national chip programs and massive data center buildouts turn AI into a domain of industrial policy rather than pure technology.
The future shape of the supply chain will be influenced by national strategy as much as corporate strategy. This creates pressure that reinforces concentration rather than loosening it.
Bubble or Not
Parts of the current AI wave show classic bubble behavior, especially in spending and valuation. The difference is that the infrastructure is strategic, and the incumbents can afford to continue building even through downturns.
This makes the long term outcome very different from the dot com era. The foundations are not completely speculative. They are essential.
The Final Reality
You are not competing with ChatGPT or Gemini. You are competing with an entire supply chain that you do not own and cannot replicate.
AI did not redistribute power. It clarified it and concentrated it. Your advantage does not sit in infrastructure because that game has already been won by giants. Your advantage sits in workflow, context and execution inside the niche you control.